
It’s been a week of planning & strategising, in-between two conference and panel-heavy weeks last week and next. On that note, do join me for the State of Open Data panel on AI next Wednesday (1pm BST), and at Open Future’s first salon looking at Business to Government Data Sharing on Thursday. Plus, I’m hoping to make it along to some of the online components of the Data Power conference.
Iterating on the case database
It looks like we’re getting into a good pattern of Monday and Wednesday team meetings, which offers a mix of focus on what we need to deliver (Monday meetings with a work planning spreadsheet) and a space to reflect on what we’re learning through the week (Wednesday meetings, where I experimented this week with bringing a sketch of the case database development for team feedback).
I’ve been getting a bit stuck with working out how to move forward the work I’ve been doing to build a dataset of cases of participatory data governance, particularly working out how to align this with our wider advocacy and practice work. So, picking up on the suggestion that it is sometimes easier to brainstorm in slides than in a prose document, I pulled together a short deck outlining where I’ve got to, and providing some rough mock ups of possible ways to expose the case study research on the Connected by Data website.

Caption: Rough mock up of Connected by Data website with four ‘calls to action’ that build on the case database work.
Feedback from Jeni and Jonathan pointed to a number of useful areas to explore more, including thinking about how far we editorialise cases to highlight our opinions on what best practice is, how we might work with partners to provide a long-term home to any case and method library resource we create, and how, when allowing users to browse by methods, we clearly communicate that effective participatory governance often requires a mix of methods.
In the deck I shared a few experiments that try and get at this latter point - visually presenting the ‘structure’ of the different cases I’ve surveyed to highlight that they involve multiple related components. I had initially thought that it might be possible to generate a ‘graph’ of relationships between components, but experimenting with mermaid.js graphs (And its nifty text to graph syntax) quickly revealed that it was going to be tricky to generate elegant presentations this way. Instead, I turned to a more linear approach to showing the structure of an example case, using icons from the noun project to start to pull out relevant facts about each component of a participatory data governance case, such as whether engagement activities are one-off, repeated, or ongoing, and whether they involved a single group over time, or multiple groups.
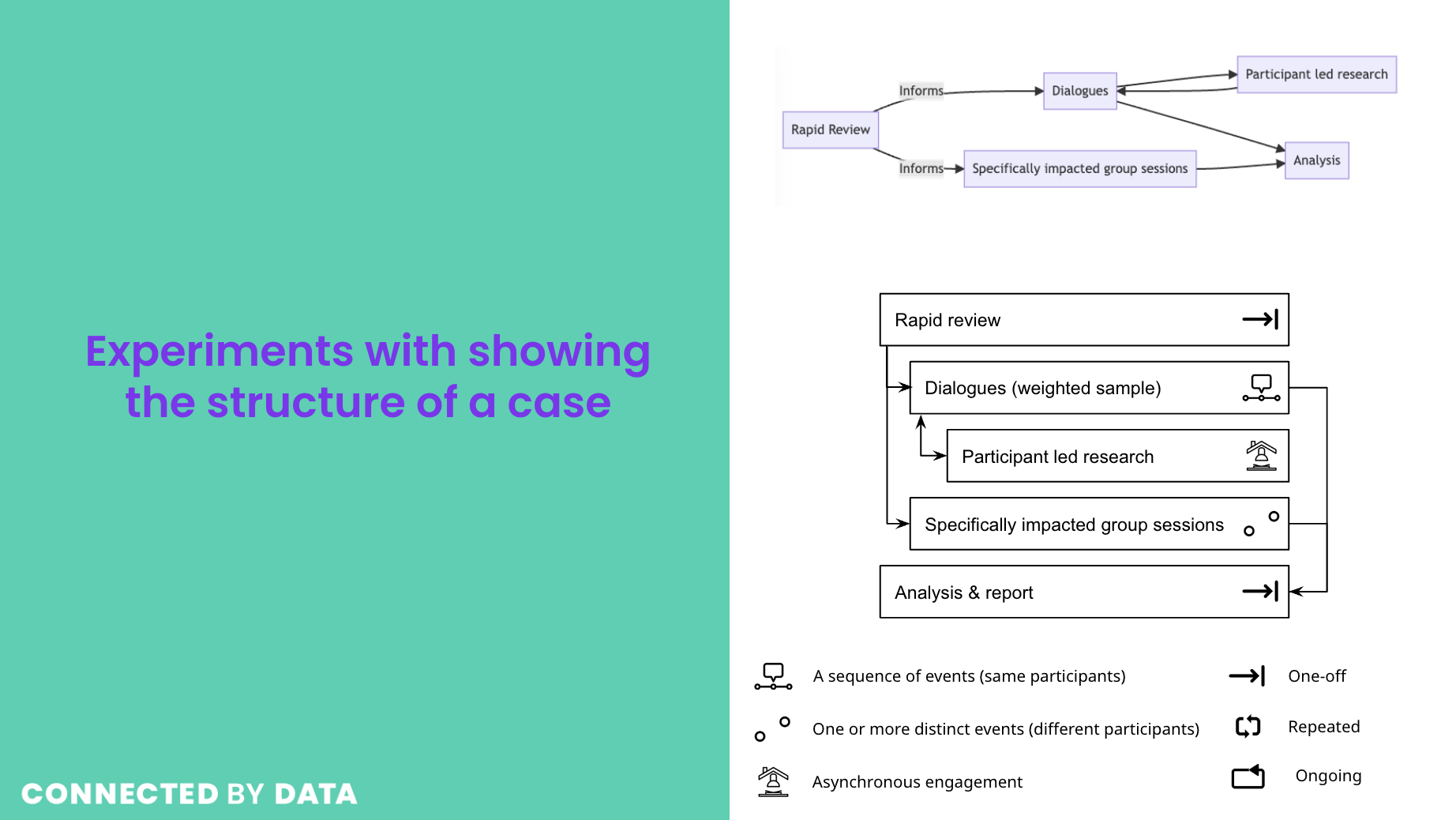
I’m going to do some work in the coming weeks to explore engaging with a designer on a next iteration of this, helping to firm up some of the key concepts we want to communicate about getting the practice of participatory governance right.
Sector selection
As Jeni has explored in her weeknotes, we spent some time this week looking at selecting a small number of sectors in which to focus our work over the next year, settling on a shortlist of debt, education and housing. I’ve started writing up a scoping document for our sectoral focus on Debt, (incorporating consumer finance and gambling) to sketch out some of the key data governance issues, key stakeholders, and potential policy influence opportunities related to data governance. At this stage, the focus is on rapid research to validate whether or not this should be a focus sector for us, and to develop our shared understanding of the scope of the sector.
Campaign strategy
I also spent a bit of time this week talking with Jonathan about our next steps of campaign planning, and how to facilitate our next stage of work on the Data Rights Bill. More on that in the coming weeks.
Other notes
Workshop on Governing Knowledge Commmons
On Monday I dropped into an online session of the Workshop on Governing Knowledge Commons set-up for discussions of ‘half baked research ideas’ linked to smart cities and knowledge commons. There were a couple of really useful insights from the discussions, including tips from Brett Fischman on making sense of complex phenomena (like adoption of smart city technology, or, indeed, collective governance of data) through analysing in different action arenas from Macro (i.e. how is the city as a whole adopting a collective approach to data governance?), to Meso (how is work in the housing sector in the city adopting collective data governance?), to Micro (how is a particular project making use of a collective approach to data governance?).
Katherine Strandberg pointed to the particular features of the Governing Knowledge Commons (GKC) framework, as opposed to Ostrom’s commons governance work, in dealing with the fact that “knowledge commons are especially likely to have impact (positive or negative) beyond the community obviously involved in creating the knowledge”, such as in cases of patients involved in rare disease research.
In response to some of my musing on how we can use our Connected by Data case research to understand the kinds of governance appropriate to different situations, Brett offered the concept of externalities as one tool to use. Depending on the data and context in play, there may be different positive or negative externalities from data collection and use to worry about, and different kinds of governance institutions may be more or less effective at managing these.
Indigenous Data Sovereignty
Thanks to Jeff Doctor for sparing the time to chat through some of the ways Indigenous tech firm Animikii are thinking about data governance, and about some of the data (and wider) issues facing Indigenous communities. We touched on the challenge of identifying the legitimate collectives that have a role in governing data, particularly in cases where the claim of states to jurisdiction over territory and peoples remains contested, and the need to recognise the ongoing struggle that many Indigenous people face to find security, and to avoid being criminalised or marginalised through data-driven forms of surveillance and control. This brings into relief some of the challenge of designing participatory data governance approaches that engage those most affected by data use, whilst respecting that the point at which individuals and communities most experience data-based harms may be the point at which they have least capacity to engage in wider governance debates.
It was also insightful, amidst the talk that sometimes comes up around the Datasphere initiative of navigating data governance in a post-Westphalian order, to be reminded of the many Indigenous nation’s claims on land, that have long challenged the settled international boundaries taken for granted in so much work. Jeff pointed me in particular to the Land Rights statement of The Council of Chiefs of the Haudenosaunee, making a connection between data rights and land rights.
RightsCon
Building on last week’s weeknotes, I added a few bits into our write up of RightsCon which you can find here.
Visualising processes
On Wednesday I had a catch up with Mel Flanagan of Nook Studios, whose work seeks to make complex processes much more accessible through careful information design. Mel shared updates on the work they have been doing to join the dots between different open government initiatives and data silos, but we also talked briefly about ways the process-visualisations developed for this could be applied in data governance dialogue processes.
Legitimate interests research
Lastly, I ended the week by firing off a few ‘test requests’ for Legitimate Interest balancing tests from a selection of companies whose privacy policies invite users to request these.
Using the Princeton-Leuven Longitudinal Privacy Policy Dataset I’ve searched for “balancing test” and then identified a number of large websites that have text in their current privacy policies to the effect that: they process certain data on the basis of legitimate interests; they have carried out balancing tests; these balancing tests can be requested by emailing them.
Conscious of the controversy from the Princeton-Radboud Study on Privacy Law Implementation which sent simulated messages to request GDPR related implementation information to a large number of websites, triggering significant work by in-house legal teams, I’ve taken care to clearly identify in the outgoing messages that this is part of Connected by Data research work, and is not strictly a customer request, so I will be interested to see what replies, if any, we get.
This will help shape any future research work into how balancing tests are currently used, particularly relevant with the upcoming details of the Data Reform Bill.